PCA on years
I used principal components analysis at the end of my last post to create a two-dimensional plot of genre based on similarities in word usage. As a reminder, here’s an improved (using all my data on the 10,000 most common words) version of that plot:
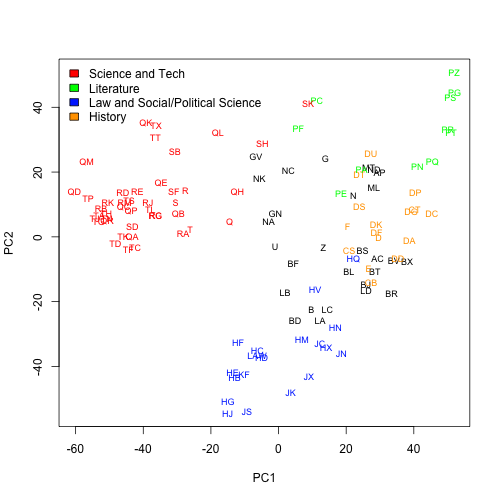
I have a professional interest in shifts in genres. But this isn’t temporal–it’s just a static depiction of genres that presumably waxed and waned over time. What can we do to make it historical?
Well, the first thing to remember is that, just as a genre can be a single text for the purposes of pca (or any other analysis), so can a year. We can drop onto that same chart all of the years from 1822 to 1922, say, shading from yellow for the early years to red for the later ones:

Now, this loading of pca dimensions onto each other is probably not kosher, and I’m pretty sure that only the directionality is for real there–ie, 1912 probably would be closer to the center of the graph if this were done perfectly. And it’s a bit of a mess.
But rather than make these two different sets live together, something I’ll get into more in a later post, we can run a separate pca analysis on just the years. Remember, pca finds the set of coordinates that discriminate most strongly between the inputs you give it. So here, the first principal component is a set of weightings for different that distinguish the most strongly between years. On one side are those that use words like the following a lot:
> paste(names(sort(comps$rotation[,1])[1:20]),collapse=“,”)
[1] “justly, circumstances, occasion, which, prudent, acknowledged, notwithstanding, disposed, rendered, commencement, circumstance, mode, pursued, excite, attended, whole, former, their, bestowed, effectually”
And on the other are years that use words like the following:
> paste(names(sort(comps$rotation[,1],decreasing=T)[1:20]),collapse=“,”)
[1] “outside, helped, background, ignored, needed, appreciation, started, back, anything, across, significance, anywhere, start, recognition, worked, out, confronted, largely, based, help”
If you click on the links to ngrams, it’s clear what these are–words that change steadily in their use over time, and are therefore good at telling years apart. Here’s a chart of every year’s vocabulary scored by the first principal component:

There are a few aberrations—pca seems to think 1871 looks like it belongs in the 1890s, which is odd—but generally it’s quite good for a system that had no idea what order the years should go in.
[Edit: Playing around with the animated version, which should go up soon, it becomes clear why 1871 is such an outlier: it has a one-year explosion of magazines in the sample, which tend to use more modern language for a variety of reasons].
So that’s the first principal component. Read no more if you only care about the useful. The later ones are stranger: where stuff either gets useless, or really interesting, or both. The thing to remember about PCA is that it finds perpendicular dimensions in the data so that there is zero correlation between two components. So if the first principal component finds terms that move up or down across the year horizon, subsequent ones will find patterns that have no overall temporal trend. In practice, that means the second component will be words that have either peak or trough towards the middle, and are higher on the ends. Here’s a link to them on ngrams. (Remember, my data is different than ngrams, so it the patterns probably stand out better if I plot them myself. But this is easy, and keeps me honest).
I think it’s possible somehow, somewhere those numbers could be useful–you could tweak the endpoints to find temporary peaks in any given period, or troughs. Not as sophisticated as trend line fitting like they used for the suppression indices in the Science paper, but possibly much faster, which is one of the great strengths of eigenvectors, I think. Anyway, that’s not really my department.
Later components lead nowhere good. On a sufficiently large dataset, I think—unless I’m missing something—the principals components from number 2 on would probably come to find words whose patterns mirror the harmonics of a string. Now, I’ve been saying for a while that digital tools are good for poststructuralists. But in the spirit of the big tent that seems to be the DH issue of the day, let me point that here’s a case where computers would be good for Pythagorean mystics or modern-day Spenglerians trying to eke out a living on the margins of the academy. Someone should run some tests on the ngrams sets to see if cyclical patterns occur more often than they should by chance: if so, Scienza Nuova, here we come!
Comments:
Ben: Last comment for today, and now I think I’…
Hank - Feb 6, 2011
Ben: Last comment for today, and now I think I’m up to date on what you’ve been thinking. I like the distinction between method and tools - it’s an important one for a whole host of reasons. One:
We readily sense that tools get used, but, personally, I think we too readily do the same for methods. These latter seem somehow larger to me - do they to you? - and so coming up with a better way of talking about how they’re developed and why might:
help us scramble out of a vocabulary of man-the-tool-user in the history of ideas and (B) situate our own use of digital “tools” in a wider context of developments in the discipline or in the humanities as a whole. Make any sense?
Possibly something useful? Topics over Time http:…
Allen Riddell - Feb 6, 2011
Possibly something useful?
Topics over Time http://citeseerx.ist.psu.edu/viewdoc/summary?doi=10.1.1.152.2460
Dynamic Topic Models http://citeseerx.ist.psu.edu/viewdoc/summary?doi=10.1.1.62.2783
@Hank It’s probably not worth concretizing, b…
Ben - Feb 6, 2011
@Hank
It’s probably not worth concretizing, but I sort of want methods to be approaches, big-picture stuff, which tools can help instantiate. Close to a strategy/tactics distinction, I guess. So yeah: I think that certain digital tools can be, if well controlled, relevant to wider developments in the field as a whole.
@Allen
Yeah, I’ve been wondering about topic modelling for a while, but just holding back from the overhead of actually learning/doing it in depth. Partly because there seem to be all these subtly different approaches - CTM, tLDA, that I don’t feel qualified to discriminate among, and partly because I know it will be a while before I could get as good an understanding of any probabilistic model as I get intuitively of the vector-space models I’m using here, even though I do believe they’re probably better. It’s a good point this might be the place to dive in: these genre groupings would be a lot smaller to start, which is probably a good thing. I’ve been wondering a lot about the interpretibility of topic model for exploration, not just classification, which is what it seems to be built for… there’s definitely something there.
Somehow David Blei, who seems to be Mr. Topic Models, has been enticed to come by the history department this week to talk about electronic archives; depending on what he says that might really start me off in a new direction.
Have you used them yourself at all? I haven’t seen any good examples of digital humanists using topic models for anything but smaller, fun projects.
I feel like PCA is pretty opaque and the results a…
Allen Riddell - Feb 6, 2011
I feel like PCA is pretty opaque and the results are hard to interpret for text. Topic modeling seems a step better and you can target it to specific hypotheses easier, IMHO. It does require a bunch more computing power. There’s a nice R package, topicmodels that you might want to check out.
Here are three examples:
Blei’s topic modeling of Science magazine
David Hall’s intellectual history/topic modeling of the linguistics journals “Studying the History of Ideas Using Topic Models”
Cameron Blevins’ topic modeling 27 years of 18th century diary entries http://historying.org/2010/04/01/topic-modeling-martha-ballards-diary/
Allen, Thanks, that Hall paper is great and I wis…
Ben - Feb 0, 2011
Allen,
Thanks, that Hall paper is great and I wish I’d seen it earlier. And I’d seen Blevins’ stuff in passing, but he goes more in depth than I thought at first. I just taught the Ulrich book last week, and it’s neat how some of the charts she spent a while creating—the decline of Ballard’s midwifery practice, say—just pop out.
I know topic modeling is the future, but I’ve just got an affection for vector models that I can actually intuit–topic modeling seems a bit too much like magic, and I’d have to write an implementation to dispel that. Also, as you say, it takes more power: I suspect that some of the established models might choke my computer against 20GB of data. Have you used the MALLET package? I’ve heard that’s better than the various R packages for some reason.
Ben, I’ve never looked at the Ulrich book. I&…
Allen Riddell - Feb 1, 2011
Ben,
I’ve never looked at the Ulrich book. I’m going to go request it now. Thanks for the reminder.
I think I get your point about being comfortable with the vector model. What I’m a little confused about is why PCA is any less removed from the word frequencies than the topic model is. Personally, I think it’s easier to explain Bayes’ rule and probability distributions than to explain an orthogonal projection matrix. But maybe you’ve had some experience explaining PCA to folks…
Allen, I definitely don’t want to dig myself …
Ben - Feb 1, 2011
Allen,
I definitely don’t want to dig myself in behind PCA, because I certainly haven’t found it that easy to explain, particularly past the first component. (That one is pretty easy, actually, which is why I like having this year rotation data on hand). And once you do explain it, you have to spend a lot of time issuing caveats, because the intuitive explanations of the axes are always going to be correlated with each other. I do think spatial transformations stay a little closer to the original data in some ways (although that’s more true for a technique like cosine similarity than what I’m doing, which requires a lot of scaling and normalizing).
I guess my intuition is that topic modeling is, as it says, modeling, while PCA is just rearranging. When I say it like that, I think that’s probably an incorrect view; my only question is whether it’s an idiosyncratically incorrect view, or one that other humanists might share. In which case, PCA might be able to find a niche.
You’ve convinced me that I need to try PCA, at…
Anonymous - Feb 2, 2011
You’ve convinced me that I need to try PCA, at least as a exploratory technique.
@Ted: You almost make it sound like a hallucinogen…
Ben - Feb 2, 2011
@Ted: You almost make it sound like a hallucinogenic. Go for it, man: expand your mind, see the higher dimensions.